
Last week an ICANN registrar, Namejuice, went off the air for the better part of the day – disappearing off the internet at approximately 8:30am, taking all domains delegated to its nameservers with it, and did not come back online until close to 11pm ET.
That was a full business day and more of complete outage for all businesses, domains, websites, and email who were using the Namejuice nameservers – something many of them were doing.
Over the course of the day, speculation abounded around the cause of the outage (and we look at some of them below). None of their customers whom I was in communcations with, nor anybody in the reddit thread reported recieving any communication from Namejuice about the cause of the outage or an ETA for restoration of service. They were simply gone, and given the lack of information there was scant basis to discern whether this was a temporary or a permanent condition.
Needless to say, as far as outages go, this wasn’t handled well by the vendor. The lessons learned make for an effective case study that validated the unifying theme of my book (sorry, I’m talking up my book here).
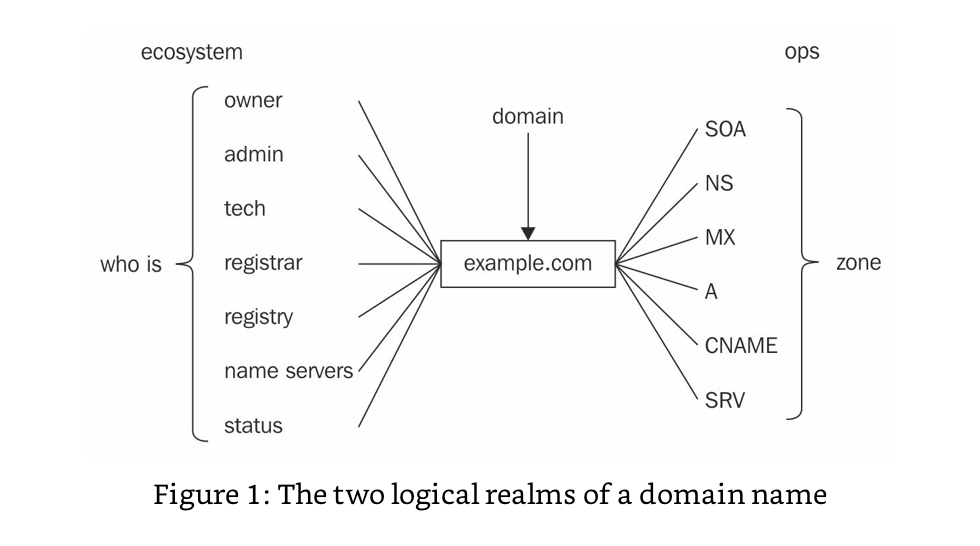
The underlying theme of Managing Mission Critical Domains and DNS is that in today’s IT landscape there is a divide between DNS operations and domain portfolio management. That divide is an artificial one, and it leads to disconnects that can result in domain outages. Those outages can take your company down, or even entire chunks of the internet, based on the dependencies of any given domain.
Namejuice’s background
Namejuice is not unknown throughout IT circles owing to their practice of allegedly soliciting customers via “domain slamming”.
They have had their ICANN accreditation suspended at least once, CIRA de-certified them as a Canadian .CA registrar, and the Canadian Competition Bureau has issued at least one warning about the practice of domain slamming to consumers.
I mention all this, because domain slamming is one of the topics covered in my book under the “common pitfalls” chapter. It relates to the various vulnerabilities companies can expose themselves to by inadvertently authorizing a transfer of their domains to a new registrar without fully understanding what that entails.
It cannot be emphasized enough that when the administrative functions of managing domain portfolios, like registering and renewing domains, are separated from the ops aspect of making sure they work on the internet; it can lead to a situation that puts your organization at risk.
Bookkeeping or accounting may have filled out the form they received in the email, thinking it was a legitimate account payable, triggering the transfer. IT goes along with it because somebody in management must have done it for a reason, right?
Then last Monday comes along and *whammo*, everything’s offline, the entire company is down and there’s nothing anybody can do about it.
Overview of the Outage
The outage began around 8:30am in the morning Sept 10, 2018 and a reddit thread in /r/sysadmin starting forming around the incident. The rumours were that the outage was caused by a power outage at Namejuice’s data center in Markham. There were a few power outages throughout the GTA that morning.
The word was that somebody at ICANN had spoken to somebody at Namejuice and they were given a 1pm ETA for the restoration of power to the data center. 1pm came and went and nothing happened:
We were able to get ahold of someone at ICANN. DROA.com data center has suffered a power outage and their backup generator failed. The power company is currently working to resolve the issues. We were given an ETA of 1PM EST to when the power is restored. Hope this helps.
However, as a subsequent redditor noted, that comment was posted from an account that was created that day and had only ever posted one comment, that one.
There are a lot of data centres in Markham. Whatever datacenter Namejuice is using couldn’t get their backup generator working, which seems like one of basics that any DC would need to get right. Even if the backup gens didn’t kick in automatically, they should have been able to manually start them. Also, had the entire data center lost power without backup, then we would have expected to have seen reports of more outages from any other outfits who were colocated within the same datacenter.
Weirder still is that the Namejuice outage appeared to be caused by a DNS failure. All four nameservers were completely offline and unresponsive to ping requests, yet, only two of those name servers looked to be within the Markham DC.
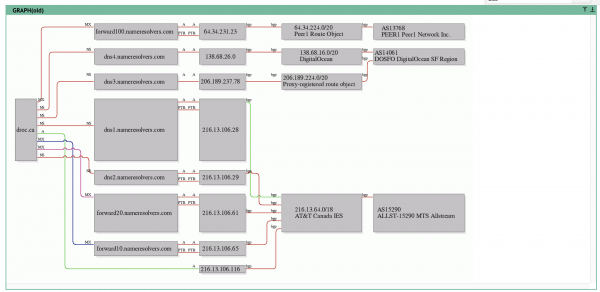
The other two nameservers were offsite, at Digital Ocean, but they were down too. Why would they be down if the outage was caused by a power failure in Markham?
I dwell on this because it leads directly to our next lesson learned from this outage, which is also in my book, under the “Nameservers Considerations” chapter, where we look at numbering and address schemes for allocating production nameservers, see below.
Rumours of ICANN de-accreditation
At one point in the day I received an email from a sysadmin acquaintance who’s company was down (an investment fund) because their domains and DNS were impacted, and he said: “GoDaddy verified that ICANN finally took them down.”
I replied quickly to this one, that had to be a flat out false rumour: There is no way an ICANN decertification would happen in such a “band-aid moment” fashion. It would be telegraphed well in advance, announced by ICANN via it’s website and all domains would have been transitioned to another registrar via a tender process.
Further, even if that all had happened, nothing ICANN does would impact the existing DNS. They don’t have some magic killswitch that just shuts down a deaccreditted registrar’s nameservers, that would be so far outside ICANN’s purview as to be draconian. The only thing that would happen in such a situation is the decertified registrar can no longer register, transfer or renew domains and their existing customers get moved to a new registrar.
Again, absent any communications from the vendor, via some out-of-band medium like Twitter, these types of rumours were bound to circulate.
This outage was possibly caused by a DDoS attack.
By the end of the day I was already skeptical of the power outage narrative and I knew it wasn’t an ICANN thing, the most likely remaining explanation was that Namejuice’s nameservers were under a DDoS attack.
My suspicions were reinforced the next morning when the CEO of another Markham datacenter I know personally discussed the events with me. He told me that somebody who peers at 151 Front experienced some degradation on their cross connects with Zayo associated with a DDoS on port 53 udp (which is DNS). The Markham IPs for Namejuice are Zayo/Allstream. It started around 8:30am.
A DDoS attack against Namejuice’s DNS would explain everything, and this is the point where we hit that next point I cover in my book under “Nameserver Considerations”. That’s the selection of the IP space your DNS provider uses to operate its nameservers on.
The path of least resistance is to simply get IP space from your upstream provider, or use the IPs assigned to you by some cloud provider and set your nameservers up on those IPs.
The problem is when you get DDoS-ed, your upstreams simply null route those IP addresses to preserve the rest of their infrastructure, and there’s nothing you can do about it until they decide to lift those null routes. Different places have different policies but in general they aren’t too keen to do it until they are sure the DDoS is over. Back when we were still on external IPs one provider’s policy was that once they dropped in a null route the soonest they would even look at it again was 24 hours later. I remember at least one DDoS where we ended up renumbering nameservers.
Ideally your DNS provider is using IPs within their own net blocks so that they are in control of their own ASN and routing announcements. That way when a DDoS comes if your upstream provider drops your routes to save themselves you at least still have the option to bring up your routes someplace else to get back online, like a DDoS mitigation solution.
Without this, you’re at the mercy of your upstream, unless, as I mentioned, you decide to completely renumber your nameserver IPs, and this is a practical option when it has to be. Of course, this only works if you can quickly get all of your hosted zones over to a new location and that new location has the capability and the willingness to deal with the DDOS which is almost certain to follow you there.
The big caveats with these tactics is that you should have all of it set up in advance. Run warm spare nameservers that you aren’t using in other locations, in a DDOS mitigated DC or have access to a reverse proxy or GRE tunnel that you can turn up when you need it.
These solutions are non-trivial to setup, I guess it just comes down to how seriously you take your clients’ uptime as to whether you would do this.
The other concern if it was a DDoS attack is that it may happen again. Was it against a Namejuice customer, who is still there? Or was it against Namejuice themselves? (Again, in my book we talk about tools like dnstop and delegation numbering schemes that provide ways to figure all this out). There are unanswered questions around how Namejuice reacted to this possible DDoS and what, if any, their DDOS mitigation capabilities are.
Registrar transfer-locks can backfire
One aspect of this outage has had be pondering what the best practice should be for transfer locks. We always say they should be on all the time until the time comes where you want to transfer out.
In this case, that would be bad advice. Even if people made it a habit to keep a local copy of their domain auth codes (good idea), it would have done them no good if the transfer lock was on and the registrar was down.
If you leave your lock off so that you can escape an out of commission and unresponsive registrar, you would want to use a registrar with enhanced security functions like 2fa and event notifications.
The other option is to leave your transfer lock on, but, as is our mantra:
Use multiple DNS providers
Is something we’ve been saying for years: use multiple DNS providers. Either in an active/active setup where you mix nameservers from multiple providers in your live delegation, or active/passive, where you run hot spares that are up to date and current with your DNS zone and have them kick in if your primary provider goes down.
That’s what our proactive nameservers does automatically. That’s failover at the nameserver level and it’s something that will work even if the rest of our platform is being DDoS-ed, because nothing within the proactive nameserver system is public facing.
To this day we’re still the only registrar providing that as a service but who are we to argue? All I know is it works and if anybody who had been on Namejuice nameservers last Monday was using it they would have had a much different Monday.
There are other options for running multiple DNS providers, we run them down on our High Availability DNS page here.
If you’re using multiple DNS providers, then you can keep your registrar transfer locks enabled, because if your registrar blows up you’ll still be online and then you can take any corrective action required once your registrar is back online. In an emergency transfer (non-responsive registrar) or complete registrar failure situation you’re looking at 3 to 5 days, minimum before anything can happen via ICANN, probably longer. So bear that in mind as you set your expire times, and be prepared to switch any secondaries to becoming primaries if your primaries are in danger of timing out or use an unpublished primary under your direct control.
The key takeaways
The lessons from all this come down as follow:
- Have a coherent internal policy on registration and renewals so that your domains don’t wind up anyplace unexpected
- Stick with providers who are known for excellent client communications and support. The mettle test for this is looking at how they behave during Black Swan Events like outages.
- Use DNS operators who run their nameservers on their own IP space and ASNs
- Use multiple DNS providers
- At the risk of sounding like “Scagnetti on Scagnetti”, Read my book
Ultimately it really doesn’t matter what caused the outage, all we really care about in the art and science of domain portfolio management is to be able to stay online whenever one of your key vendors experiences an outage.
The easyDNS mantra for 20 years is…
DNS is something nobody cares about… until it stops working.
But outages can and will happen to everyone, sooner or later. Take the time to really think about your DNS and domain portfolio before the outage hits, then you’ll be ready for it.
>>However, as a subsequent redditor noted, that comment was posted from an account that was created that day and had only ever posted one comment, that one.<<
I'm not sure if you were talking about my comment or not. It came across harsh and I don't think people too kindly to it. My intention was for everyone to be careful. There are so many things blindly told now a days on reddit or anywhere that people just accept. I honestly believe the person I called out was from Namejuice or an affiliate. The lack of information surrounding this event is absolutely crazy, and I appreciate you writing this article to surmise what I was thinking. Thank you for your article again, very well put.