As we all know, on Friday Oct 21, 2016 DNS provider Dynect was severely impacted by a big DDoS attack which has since been attributed to the Mirai Botnet. (interesting to note that “Mirai” means “future” in Japanese).
Briefly: The Mirai Botnet is constructed by commandeering network connected Internet of Things (IoT) devices such as remote cameras, or any other device somebody thought would be “neat” to connect to the Internet, albeit with crappy security like a default admin password. These devices, aggregate into the 10’s of thousands or potentially more and can be coordinated to launch traffic at a target like a website (such as the possibly world-record setting DDoS against security researcher Brian Krebs recently – also attributed to Mirai), or the nameservers for a target. Which is what happened to Dynect on Friday.
As we know too well, when you bring down a target’s nameservers, you effectively disappear that target from the Internet, and unfortunately you also bring down every other domain name that is using the same set of nameservers (unless they have additional nameservers, see below).
DDoS attacks are nothing new, and neither are attacks against DNS infrastructure. God knows we’ve had our fair share here at easyDNS and I still have the psychological scars from a few of them.
The fact is they are only getting worse as time goes on:
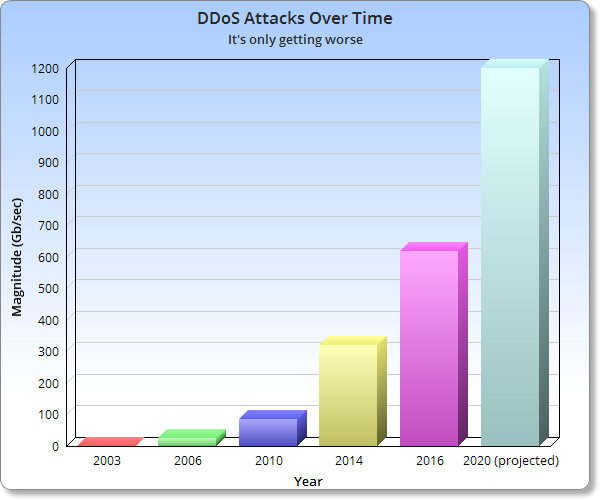
This graph is for the DDoS chapter in my upcoming O’Reilly book (which is almost finally done, thank gawd), the data points are as follows:
- 2003: a 500 Mb/sec DDoS against easyDNS – ending our glorious 5 years of 100% DNS uptime since launching in 1998. Boo. Hiss.
- 2006: 25 Gb/sec against us again. Turned out to be some guy pissed off at a HYIP (ponzi) domain that fleeced him. Go figure. Which is why when we find a HYIP domain on easyDNS we instantly terminate it.
- 2010: 85 Gb/sec attack against DNSMadeEasy. Posited to be record setting at the time. That one prompted us to write the original version of our “DOS attacks and DNS: How to Stay Up When Your DNS Provider is Down” post.
- 2014: 300 – 400 Gb/Sec NTP reflection attack. Whoa. Scary. If we hadn’t already decided the way to deal with these was via multiple DNS providers, we would have done so right about here.
- 2016: 600 Gb/Sec Mirai Botnet against Krebs On Security. Same thing used against Dynect, comprised of Internet of Shit devices.
- 2020 (projected) 1.2Tb/sec: In 2014 DDoS Mitigation firm Prolexic issued a white paper with datapoint from the graph: Predicting that 1.2 Tb/sec attacks would be a reality by 2020.
Not in the graph: days after the 2016 Krebs Online attack, French ISP OVH reported one at “double the magnitude” that hit Krebs. If true, we’re in the 1.2 Tb/sec ballpark, a few years early.
The pattern is clear, this is only getting worse.
If you are employing mitigation devices, or using third-party scrubbing services you are taking an “arms race” approach and you are always fighting the last war. There will always come a bigger botnet, there will be always a larger attack.
The traditional silver bullets won’t work
In the past there was debate that things like BCP38 could be a silver bullet against DDoS attacks (BCP38 is network ingress filtering) which would prevent spoofed traffic from entering the network of a DDoS target. Which is true if the attack traffic is using forged headers and spoofing where the packets are originating from. This was a common feature to DDoS attack traffic in the past.
The uptake of BCP38 has been slow-to-none given the problem that ROI for implementing it is “asymmetric” (to use Paul Vixie’s phrase when he analyzes this issue), meaning that the party who makes the investment to implement BCP 38 wouldn’t be the same party who would reap the direct benefits of it.
But since DNS attacks in particular have become mainly reflection and amplification attacks, BCP38 doesn’t necessarily help. My understanding so far the Mirai attack is the same: the packets aren’t forged or spoofed so BCP 38 wouldn’t make a difference.
Even the problem of too many open resolvers being present on the internet, a big factor in DNS amplification and reflection attacks, is less of an issue here. Mirai attacks don’t necessarily need or use open resolvers because these are just dead stupid devices generating queries from within their own networks and they’ll simply hit their local resolver service (that being the ISP or whatever is configured).
Who Did It? Was it the Russians?
(Those wanting to skip my possibly meandering analysis of the “deep politics” behind the attack may want to to simply skip to the “What Do I Do About It?“, below.)
The source code to Mirai was known to have been leaked into the wild prior to Friday’s attack so the hit on Dynect could have been quite literally… anybody with knowledge of the Internet’s back alleys and the requisite skills to set it up and deploy it.
Predictably, I’ve already seen a lot of nonsense floating around the ‘net about who it “could” have been and why they did it, like this:
“The DDOS Attacks Are Most Likely A FALSE FLAG By The Clinton Camp To Blame RUSSIA And WIKILEAKS, But WIKILEAKS Is Strangely Blaming Supporters”
 In another example, Representative Marsha Blackburn (R-Tennessee) went on CNN and somehow drew a straight line to Friday’s attack from the failure of SOPA to pass (remember that?) It’s a strange allegation. Think of it as arguing that cancer could be eliminated if only Green Day won the World Series. It’s an incomprehensible premise that just makes no sense. Perhaps the most frightening realization to emerge from Friday is that Blackburn (and presumably others like her) comprise the US Senate’s Communications and Technology Subcommittee.
In another example, Representative Marsha Blackburn (R-Tennessee) went on CNN and somehow drew a straight line to Friday’s attack from the failure of SOPA to pass (remember that?) It’s a strange allegation. Think of it as arguing that cancer could be eliminated if only Green Day won the World Series. It’s an incomprehensible premise that just makes no sense. Perhaps the most frightening realization to emerge from Friday is that Blackburn (and presumably others like her) comprise the US Senate’s Communications and Technology Subcommittee.
Granted, I did find the timing “odd” that the attack happened a mere two days after I wrote here on the easyBlog about how deliberately provoking a cyberwar with Russia (as Joe Biden indicated the US would on “Meet The Press” the prior weekend), would end badly. I personally attribute that to coincidence as opposed to an opening salvo.
A hacker group called “New World Hacking” actually claimed responsibility for the attack, but it’s hard to say if it was really them (some security types I’m in contact with are skeptical).
So Who Actually Did Do It Then?
Attention to the Mirai botnet emerged after Brian Krebs wrote an article exposing a shadowy group based in Israel called “vDos”, which was billing itself as an “IP Stresser Service” (a service that is supposed to exist to “stress test” your network for DDoS attacks). It turned out they weren’t really running an “IP stresser” service but a full-on “DDoS-for-hire” service, and his expose earned him the receiving end of the largest attack on record, forcing his mitigation service, Prolexic (now owned by Akamai) to dump him (in their defense, that’s what happens anywhere when you get hit with a DDoS you cannot fully handle. You don’t have much of a choice).
After that happened, the Mirai botnet source leaked, so the field has massively expanded in terms of who could do it. As Krebs delved deeper into what happened he also discovered that a DDoS mitigation firm called BackConnect had employed a questionable tactic (hijacking the BGP prefixes of an external entity) in claimed self-defense against an attack. His further analysis was that the company had a history of doing it.
The emergence of “Defensive BGP attacks” became a vigorous discussion on the North American Network Operators Group (NANOG) mailing list and Dyn scurity researcher Doug Mallory gave a talk on the subject at a NANOG meeting on Thursday – the day before the attack.
I don’t know who did it and I don’t have the inside track on any suspects. The timing could be coincidence and because the source code is out there, it could be anybody. But tracing through the Krebs On Security sequence, including the vDos operations Krebs exposed (the two men who ran it were arrested in Israel after Krebs’ story broke), and proceed through the NANOG thread and then Doug Mallory’s talk and you would probably be lot closer to what actually happened. This avenue of investigation seems more promising than Russians, rogue-DNC staffers, Wikileaks or hyper-dimensional grey aliens.
What Do I Do About It?
As KrebsOnSecurity (among others) has observed:
“DDoS mitigation firms simply did not count on the size of these attacks increasing so quickly overnight, and are now scrambling to secure far greater capacity to handle much larger attacks concurrently.”
When employing DDoS mitigation gear head-on or external scrubbing centers, you are in an arms race and fighting the last war. That’s not to say you shouldn’t employ these devices (far from it, we use Cloudflare, StackPath, and Koddos and every time I think about how much fscking money we spend on DDoS mitigation it pisses me off because we can’t not do it and we can still get taken down – and so can anybody else).
But wait, there’s more:
It’s not just DDoS attacks (Sorry).
Not all DNS outages are caused by DDoS attacks. Other things cause them too. The number one cause of Data Center outages is actually UPS and power failure (although the fastest growing cause according to that same study is cybercrime). But hopefully you don’t have all of your DNS servers in one data center. If we had to pick the single biggest DNS outage in terms of the number of domains taken offline, I would guess it was the great Godaddy outage of 2012 which took down millions of domains for approximately 8 hours and was attributed to corrupted routing tables.
So as mentioned in our “DNS and DoS Attacks, How to Stay Up When Your DNS Provider Goes Down” (which still gets boatloads of traffic every time there is a major DNS outage), the magic bullet for maintaining High Availability DNS even when your main DNS solution goes down is:
Use Multiple DNS Solutions
If the point hasn’t been made yet, I’ll restate it here: No matter how much redundancy, how much network capacity, how many POPs worldwide, all DNS providers are a logical SPOF unto themselves:
So if you absolutely, positively have to have 100% DNS availability all the time, you must:
- Use multiple DNS providers or solutions
- Have a coherent methodology for syndicating your zones across those solutions
- Be able to track the health of each component of your “DNS mosaic” (I just made that up)
- Have the ability to switch / enable or disable components as required
and, the one piece which all of the above hinges on, usually the one part you usually cannot do once “The Black Swan Event” has started is to
- Have it all setup in advance.
At easyDNS this has been our mantra for years and we’ve created a number of tools and systems to provide that ability. As an easyDNS member you received our email directing you to this article because:
- We’ve been flooded with questions from our customers since the Friday attack asking what we know about it and what we can do about it.
- There are numerous methods already in place in the control panel to facilitate this:
High Availability DNS Methods at easyDNS
- Proactive Nameservers: Setup another set of namservers and automatically switch them in if your main ones go down. We use this here at easyDNS to keep the control panel online if we get hit hard on our main easyDNS nameservers. The favourite combo is to add Route 53 DNS via easyRoute53
- DNS Integrations: Again – Amazon Route53 is setup seamlessly either using your own account or via our managed Route 53 (easyRoute53). We also have integrations into CIRA’s D-Zone, Linode and Zoneedit – yes, we now own Zoneedit but it’s operated as a stand-alone unit and the nameservers operate on separate networks and different data centers than those of easyDNS.
- Plain vanilla DNS mirroring: Use zone transfers to any third-party nameservers (or have our slave from a third-party master).
If you’re new to easyDNS you can sign up for any of these options via the High Availability DNS page.
Leave a Reply