
With our recent ArticNames acquisition we inherited a few clients who wanted to consolidate their websites here. One of them is a cabal of retired or semi-retired policy big wigs who write pseudonymously under the moniker Barrelstrength, (their web host was a completely different company, otherwise all of the following would have been moot).
Their problem? Their webmaster died unexpectedly in February, possibly an early, undocumented Coronavirus fatality. The Barrelstrength crew commemorated him here and here, it sounds like he was a pretty interesting guy. It was somewhat unsettling to realize that he was only 53 (I will turn that age in a few months).
So, here’s the complicating incident. A cardinal error was made, one we caution people against incessantly, both as individuals and companies. Yet it continues to happen time and again: the webmaster registered the original domain under his own name. Now that he’s passed on, without an heir apparent to assume his affairs and execute his estate, at least nobody who would know what to do in this situation, the domain is beyond the reach from the rest of the crew. Same with the web hosting account that houses the domain.
The gang then decided to register a new domain, set up a Wordpress site on easyPress, and then migrate the content over, which I thought would be easy, until I realized the full extent of the problem:
All we have are some author level accounts to the WP control panel, however, none of those author accounts have admin level access.
That means:
- Nobody can’t access the built in-data exporter in the WP tools menu
- We can’t install any plugins on the source site to do anything that would make our job easier
- We can’t edit the theme or the settings to refresh the website to the new URL
Barrelstrength has been around since 2012, and has nearly 1,700 long-form posts across more than a half-dozen contributors. It wasn’t feasible to copy and paste it all.
What to do?
We were saved by one lucky break: The setting for the RSS feed was set to include full text, and not summary:

Without this, we would be completely screwed.
We can page through everything in the website by incrementing the $_GET[‘paged’] variable in the various RSS feed URLs and because full text is enabled we can grab the full content for all the posts.
All we need to do now is figure out some way, preferably some plugin, that will let us do that, and then import the feed into their respective posts on this end.
Most of the aggregators like FeedWordPress or WP RSS Aggregator don’t do it, they just look at the most recent posts in the feed and will then track on a go-forward basis. I couldn’t find any aggregator that would seek to the far end of the feed and grab everything.
Then a freelancer I know suggested using an autoblogger plugin, like WPeMatico. Bingo.
I wasn’t sure which of the premium plugins I’d need to get exactly what I wanted, but the project lead was pretty responsive on my pre-sale questions and talked me through some ideas on how to do what I wanted and I wouldn’t even need the upgrade, it turned out.
Setting it Up
One realization was that any given “campaign” within WPeMatico would reblog all the content under the same author
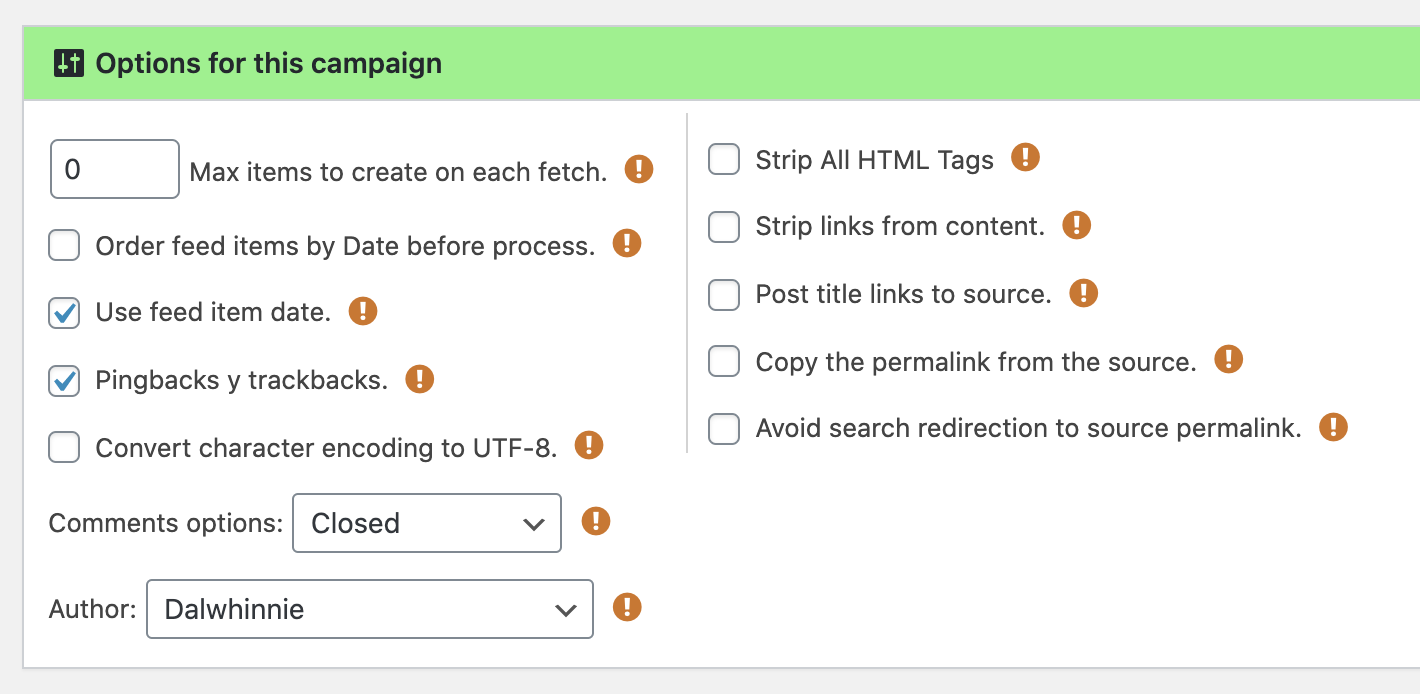
That meant setting it up to page through 160-ish pages of the main rss feed wasn’t going to work unless we wanted all the content under one author, which we don’t want.
Fortunately, Wordpress exposes a lot of RSS feeds including author feeds, via /author/[authorname]/feed so instead I just set up a separate camaign for each author.
Under each campaign, I’d add 10 feeds, each one would pull a single page of 10 items from the remote site:
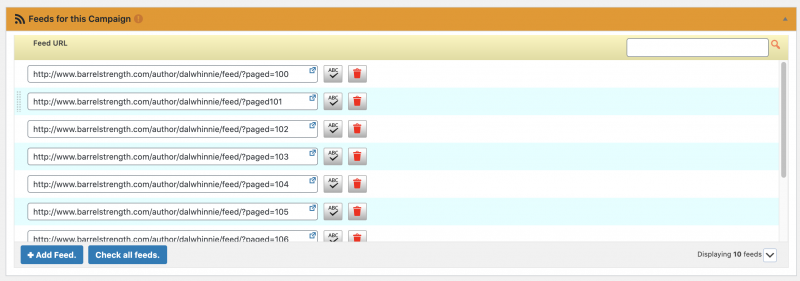
And for the more prolific authors who had a boatload of posts, I’d just break that out into multiple campaigns, 10 feeds per campaign. Doing so was easy because you could just “duplicate” a campaign, and then go in and update the paged for each one.
Only one last problem:
When dealing with all the older posts, due to some internal logic within WPeMatic, it decides it would be better to timestamp them all with the current date instead of preserving the original date, even with Use Feed Item Date enabled within the campaign.
The problem seemed to be in the global settings (which I cannot for the life of me find right now), which said in effect “If the post is older than X, use the current date”, and seemed to be doing that even when it wasn’t checked.
So, I installed a plugin editor hoping that it would be easy to find the code snippet where a fetched post date is decided and nudge it toward doing what I wanted. Fortunately it was pretty easy:
/**
* Processes an item: parses and filters
* @param $feed object Feed database object
* @param $item object SimplePie_Item object
* @return true si lo procesó
*/
function processItem($feed, $item, $feedurl) {
global $wpdb, $realcount;
trigger_error(sprintf('' . __('Processing item %1s', 'wpematico' ),$item->get_title().'' ),E_USER_NOTICE);
$this->current_item = array();
// Get the source Permalink trying to redirect if is set.
$this->current_item['permalink'] = $this->getReadUrl($item->get_permalink(), $this->campaign);
// First exclude filters
if ( $this->exclude_filters($this->current_item,$this->campaign,$feed,$item )) {
return -1 ; // resta este item del total
}
// Item date
$itemdate = $item->get_date('U');
$this->current_item['date'] = null;
if($this->campaign['campaign_feeddate']) {
if (($itemdate > $this->campaign['lastrun']) && $itemdate < current_time('timestamp', 1)) { $this->current_item['date'] = $itemdate;
trigger_error(__('Assigning original date to post.', 'wpematico' ),E_USER_NOTICE);
} else {
// DBUG
$this->current_item['date'] = $itemdate;
trigger_error(__('Assigning original date to post.', 'wpematico' ),E_USER_NOTICE);
//trigger_error(__('Original date out of range. Assigning current date to post.', 'wpematico' ) ,E_USER_NOTICE);
}
}
It started at line 284 in the campaign_fetch.php file and I just commented out the line that deemed the original date to be out of scope, copied in the earlier line that gets the post date, and that was all there was to it.
From there it was just a matter of firing the campaigns, which I did manually. It took multiple passes, so I just kept refiring it whenever it times out.
I had setup a spreadsheet to track how many posts there were originally and I managed to get between 83% and 100% of each author’s posts, 87% overall, which was not bad considering the alternatives.
The only thing I haven’t gotten are the comments, sadly. However, we have close to a year before the old site expires so we can fill in the gaps gradually and maybe in the meantime we can find some solution for the comments, they too are accessible via RSS for each post, we just need a way to import them as comments on the new site.
Then, after the old site falls off the edge of the world next year, we will try to re-register it via a domain dropcatching service, at which point we can 301 redirect all the remaining traffic and deep links to the new site.
All of the above would have been unnecessary had the project leads followed our advice we have flogged incessantly throughout the years:
Always reg your domains in your own name, even when you use a third-party to do it.
Leave a Reply